RCU概念
Rcu数据结构是基于rcu机制实现的数据结构。RCU(Read-Copy Update),顾名思义就是读-拷贝修改,它是基于其原理命名的。对于被RCU保护的共享数据结构,只读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个类似回调(callback)机制(未必必须是回调机制)在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。前面讲过在Allocator的设计中,对内存的回收是带有时间戳用来对内存进行延迟释放。这点是专门对rcu数据进行释放,默认时间是30S。rcu机制可以实现单写多读情况下的高性能无锁并发。在针对搜索引擎,单写多读情况下,简直太友好。
Zsearch下RCU数据结构
zsearch下rcu数据结构包括了vector、list、bitlist、set、byte_vector、hash_map、roaring_bitmap等数据结构实现。其中主要介绍学习bitlist和byte_vector和roaring_bitmap。
1. rcu-bitset
bitset数据结构用每一个bit位来表示信息,这样就能够进行大容量的来表示信息。bitset数据结构中主要有以下成员函数:
/**
* 设置某一位为1
* @param pos
*/
inline void set(size_type pos);
/**
* 清除某一位
* @param pos
*/
inline void clear(size_type pos)
/**
* 反转某一位
* @param pos
*/
inline void flip(size_type pos)
/**
* 检查某一位是否设置
* @param pos
* @return 为0为未设置,非0为设置
*/
inline chunk_type check(size_type pos)
/**
* 重置可用bit位大小
* @param bit_size
*/
void resize(size_type bit_size)
其中bit为最小chunk——size为uint32的整数。bitset的操作主要有四中操作:
#define BIT_SET(buf, pos) ((buf) |= (1<<(pos))) //置某位为1
#define BIT_CLEAR(buf, pos) ((buf) &= ~(1<<(pos))) //某位清0
#define BIT_FLIP(buf, pos) ((buf) ^= (1<<(pos))) //翻转1位
#define BIT_CHECK(buf, pos) ((buf) & (1<<(pos))) //check某位是否置1
bitset中涉及RCU主要在resize函数中,因为当buf的长度不够的时候,bitset会自动申请新的内存来拓展新的bufsize。此时对于线程的写操作如果是单线程,在保证执行代码顺序的情况下,指针替换是原子性的操作。
// 申请一块连续的缓存大小
size_type buf_size = chunk_size * sizeof(chunk_type);
char *buf = (char *) Z_MALLOC(GetAllocator(), buf_size);
memset(buf, init_set_ ? 0xff : 0x00, buf_size);
MEMORY_BARRIER //内存屏障
char *old_buf = NULL;
// 复制老数据
if (buf_) {
memcpy(buf, (void *) buf_, buf_size_);
old_buf = (char *) buf_;
}
MEMORY_BARRIER
buf_ = (chunk_type *) buf; //指针赋值是原子操作
bit_size_ = bit_size;
buf_size_ = buf_size;
// 清空老数据
Z_FREE(GetAllocator(), old_buf, true);
由于单线程下指针的赋值是自带原子性的操作,所以在buf替换的地方是不需要加锁等操作的,但是前提必须是要保证代码的逻辑有序执行,当前基于多核的CPU由于缓存和多核同步等操作存在着代码的乱序执行,这个CPU的乱序很复杂。背后的底层机制涉及到CPU的很多知识,其中查询的资料中有两篇文章写得很好,可以一窥原理。《深入理解 Linux RCU 之从硬件说起》,《深入理解 Linux RCU 从硬件说起之内存屏障》讲的非常详细并且比较容易理解。
- 首先第一步先申请新的内存,同时初始化内存。
- 设置内存屏障,因为下面开始要拷贝数据,必须要保证初始化是在拷贝之前做,不然未初始化内存是存在有些bitwei位非0
- 拷贝旧的buf数据到新开辟的内存中。拷贝完成设置内存屏障。
- 将新的内存指针给老的buf_指针该步骤是原子操作,针对一个写线程不需要加保护。但是要保证的是旧的数据已经完成拷贝到新的内存中,这个顺序不能乱,所以在指针赋值前加内存屏障。
- 释放老的oldbuf,该释放是内存延时释放,理论上讲,该内存的释放要保证所有线程都已经对该内存操作完的基础上进行释放。否则试想一下会发生什么,但是实际中读操作只是简单读取并不会长时间持有该指针,db中延时30S释放内存是合理的。
2. rcu_byte_vector
基础的数据结构中还实现了另外一个数据结构bytevector,可以这么认为这个存储结构的作用,就是可以存储任何对象,因为该存储的单元只是固定长度的byte位。rcu_byte_vector的成员函数和成员变量如下:
char *get_data() {
return (char *) (this) + sizeof(rcu_byte_vector);
}
size_t get_data_size() {
return element_size_ * size_;
}
char *operator[](int32 idx) {
return get(idx);
}
char *get(int32 idx) {
if (idx >= size_)
return NULL;
return get_data() + (idx * element_size_);
}
protected:
uint16 size_; //元素个数
uint16 element_size_; //元素的内存长度
- get_data函数中实现了返回当前该byte数据的指针,get()操作实现了返回当前索引元素的指针。
3. bitmap和rcu_roaring_bitmap
在索引的建立中,倒排索引的存储都是用bitmap来存储,比如我们建立了有序的docID,那么对于字段我们可以用0或者1来表示某个索引名是都存在该doc中,比如我们在广告的fcid查询中我们可以对fcid建立倒排,比如对于fcid=50003的fcid,我们可以建立如下倒排:
bitmap 1 0 0 0 1 0 1 0 1 ......
docid 1 2 3 4 5 6 7 8 9 ......
第一行就是fcid为50003的倒排存在bitmap中的情况,bitmap的位置代表的是docid的序列号,docid是有序的。如果某个对应doc中存在该fcidz则置为1表示存在于该doc中。可以看到一般情况下该倒排链会很长,因为一般商品库的商品都是很多的。设置成bitmap会很省空间一个字节就表示8个doc信息,同时在多个倒排链进行逻辑运算的时候,基于bit的位操作会比其他数据的操作快很多,但是对于海量的数据而言这样还是不够省空间并且操作的够快。从上面的bitmap也可以看出来,其实对于海量的数据而言,有可能会出现大量的连续为0的数据,其实这样是可以进行压缩的,所以就出现了许多的高性能压缩算法。
3.1 FastBit
FastBit是一种位图压缩算法,其中有一个核心的bitmap压缩算法WAH算法这个算法感觉很有意思,压缩率也很高,并且在对多个bitmap进行逻辑运算的时候不需要解压就可以进行运算。
1. WAH算法
WAH算法的压缩原理是将数据流分为literal_word和fill_word两种,分别对不同的数据进行处理,对连续出现的bit机型压缩。
- WAH算法的word位长为32位4个字节,其中word分为两种word,literal_word和fill_word两种,其中literal_word是专门存放正常0和1交叉出现的区间字段,而fill_word则是存放连续的0或者1,如下图所示:
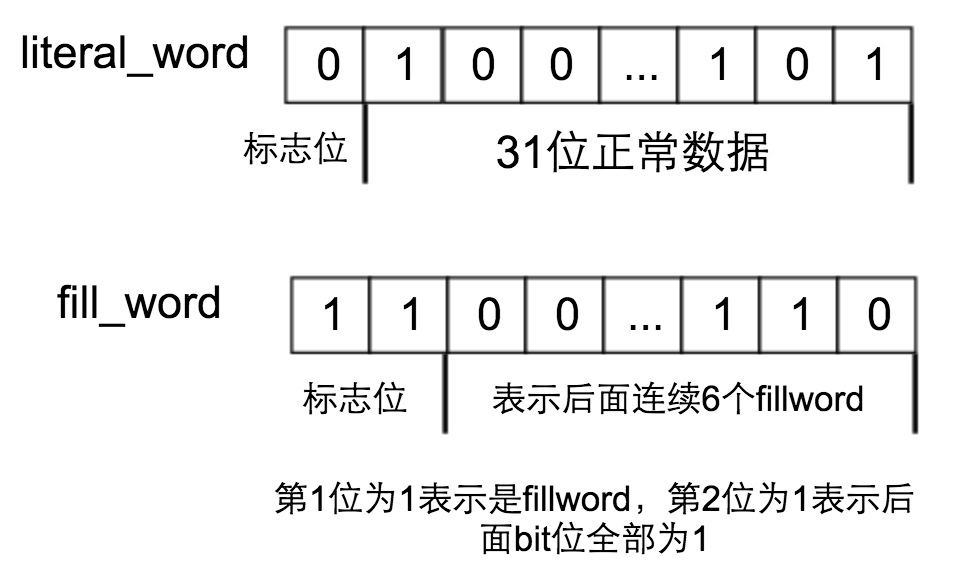
其中literal_word的最高为是0,代表着该word是一个常规的word存放的是正常数据,而fillword的最高位是1,另外次高位如果为0那么说明该word后面全是为0的word,如果为1则后面word是全是为1的word。fillword剩下30位存放的是有多少个fillword块,所以fillword能表示最大2^30个连续的fillword个数。
下面是对5456bit的二进制流进行压缩的流程:
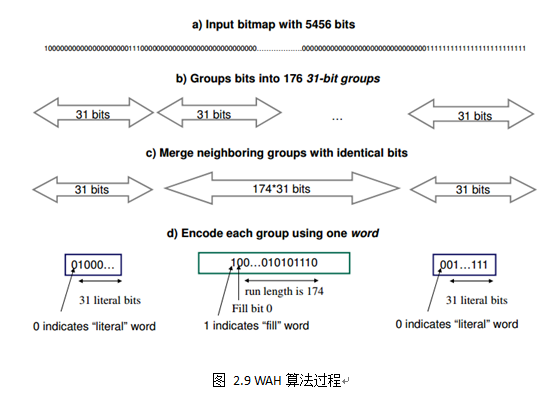
可以看到这个5456bit位压缩完只需要三个字节,这种情况下很是和倒排链很稀疏的场景,压缩了会很高很高。WHA算法还有另外一个很好地性质,就是在进行逻辑运算的时候不需要解压就可以进行运算。比如对于literalword进行AND运算由于,第一位都一样不受影响,后面31位都是真实的数据AND操作不受影响。而对于fillword的AND运算假设:
group1=10"5"(0...0101) 表示后面连着5个全是0的fillword
group2=11"1"(0...0001) 表示后面连着1个全是1的fillword
group1 和 group2进行AND操作得到group3
group3=10"1"(0...0001) 表示5*32个全是0的bit位和1个32位AND后是一个32位全是0的bitlist和未压缩中AND得到的结果是一样的,真的很神奇。
2. Concise算法
Concise算法是WHA算法一种改进,压缩率会更高,Concise算法和WHA算法区别在于
- 第一位0表示fillword,1表示literalword,次高位和WHA算法保持一致。
- 紧接着5个bit位的值n记录了在第n位进行01挥着10翻转。
- 剩下25位表示紧接着后面有多少fillword。
fillword具体结构如下图所示:

该算法对于逻辑运算是不友好的,需要解压才能进行逻辑运算,这个比较劣势。
3.2 Roaring_bitmap
前面两种压缩算法思路是大概一样的都是对重复的数据进行记录,来达到压缩的目的。Roaring bitmap 使用另一种方法来对bitmap进行压缩。
- 首先先把bitmap按照长度65535分块,比如第一个chunk块是docid从0-65535的,第二个chunk是65535-131071.
- 然后再用<商数,余数>来表示每一组ID。此时会发现把所有的数据都固定到了固定长度为65535的chunk块内了。
- 此时我们对于每个chunk的数据进行统计,如果块内数据小于4096那就用数组来存储这些数据,如果大于4096的大数据块我们就用bitset来存储。明显能看出来该算法在储存数据时是从分考虑了数据的稀疏和稠密的状态的。
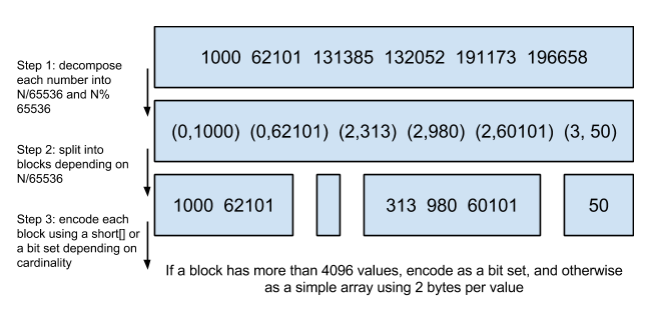
首先对于roaring bitmap算法中为什么用65535和4096这个数值来作为临界点,其实是有依据的,其中65535是两个字节表示的最大数字,并且刚好一个short可以搞定。如果选择4个字节整型该数值十几亿太大,如果选用三个字节又会出现字节浪费。所以选用65535这个数字,65535/8=8192字节该长度是恒定的,而在用array存数据时使用的是2个字节的short,因为要表示4096用char类型还不行,没办法用两个字节浪费了一点内存。此时表示array的2个字节,2*4096刚好是和用bitset表示的大块的字节数一致的,所以选取了4096这个特殊的数字。下面的图就能说明一切:
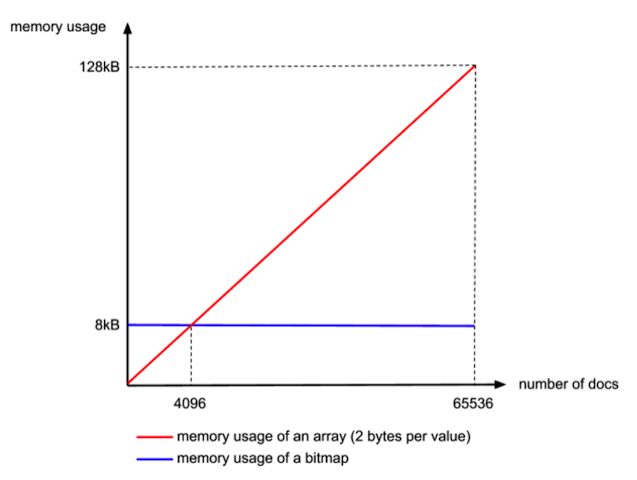
Roaring_bitmap查找和删除操作也很方便,可以说非常方便,所以在Lucene5.0后就使用了roaringbitmap作为倒排的基础数据结构。
- 查找操作,如果要查找某个整数是不是存在于bitmap中,首先除以65535得到商数定位chunk块的位置,如果该块内数据少于4096,由于数据是有序的可以使用二分查找来查找该数据,可以的出来最坏情况下循环12次就可以查找到该数据。速度非常快。如果是bitmap直接获取到余数,访问该余数对应的bitmap值就1就是存在0是不存在。
- 数据插入和删除操作,首先如果是一个数组容器,直接插入,如果刚好超过4096则需要数据重置为bitmap,如果删除一个bitma可能退化为array,这几种情况都有可能发生,需要做好边界判断和处理。
- 逻辑操作,两个roaringbitmap进行对比时,有四种情况,array和bitmap,array和array,bitmap和array,bitmap和bitmap,分四种情况分别进行逻辑运算。
roaring bitmap的性能很好,兼顾内存和性能zsearch底层倒排是使用该算法进行倒排联合索引。
总结
本文重点讲解rcu和引擎底层的数据结构,了解数据结构对于下一步的索引构建过程也会有一个更好理解。
roaring bitmap官网 http://roaringbitmap.org/ roaring bitmap实现 https://github.com/RoaringBitmap