搜索引擎整体实现
部门搜索引擎经过几次框架上的重构,框架改了好几版,当前框架较为稳定,并且性能也很好,其中有很多值得学习的地方。整体当前搜索框架如下面所示:
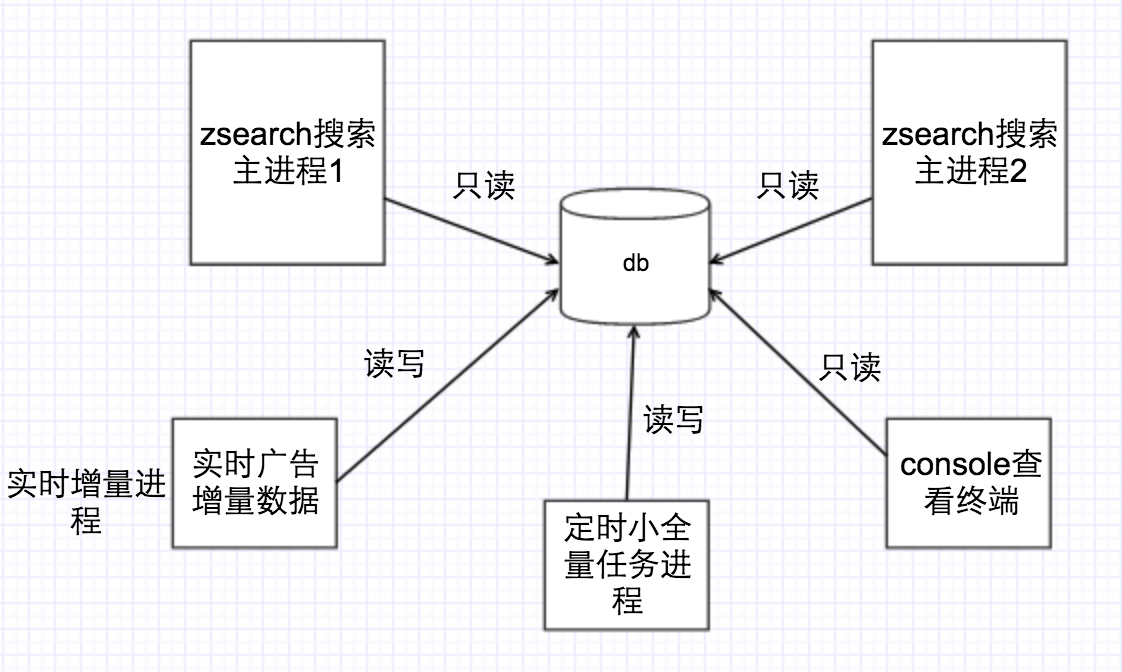
1.存储DB的设计
首先先要来说说数据db这块,因为搜索用的db以前是用sqlite数据库,引擎加载加载数据库很慢,并且重启代价很大这个问题比较严重,假如某个节点崩溃,恢复起来会很麻烦,同时数据在磁盘上访问效率也比较慢。针对以上问题组长开发了基于mmap共享内存的技术,将db数据touch到内存中去,同时支持多个实例读写,首先文件映射到内存中,在读写操作中少了内核空间到用户空间的拷贝过程,效率提升很多,另外在内存中查找速度会快很多。同时由于db数据常驻内存,在重启引擎的时候度会非常快速好处很多。整个引擎的db内存使用框架如下:
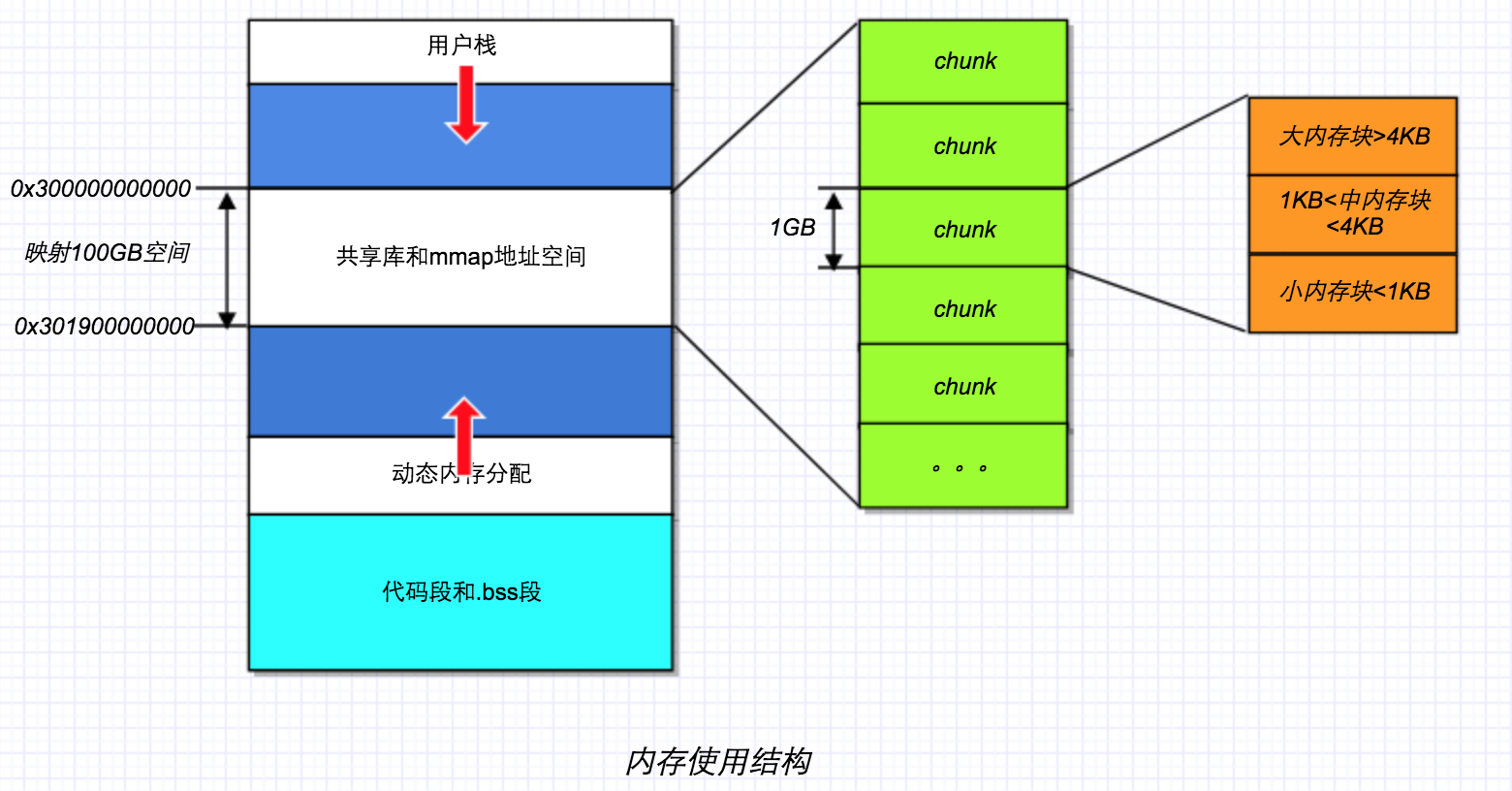
由于64位操作系统进程地址空间很大,在栈和堆空间增长的中间开辟一段内存共计100GB大小,用来映射数据文件。其中整个内存每1GB分一个chunk块作为一个db。每个db中分配了三种内存类型小块中块大块。内存的管理、分配和回收都是由一个metadata文件来储存。
2.DB中的metadata
如何对内存的分配释放,记录db中的索引信息等关键信息进行储存,metadata中需要设计一套详细的信息。zdb中metadata中存放的详细信息如下所示,很值的拿来学习。
/**
* db元信息
*/
struct DbMetadata {
int32 key_id; // 对应的key_id,一个进程不允许2个key_id一样的db同时attach
bool touch; // 创建新页是否touch到内存
DbStatus status; // 状态,三种状态1,初始化,2,正在attach,3正常
time_t create_time; // 创建时间
int32 create_pid; // 创建进程id
int32 version_id; // 创建时版本号
int32 writer; // 写进程id
int32 delay_free_sec; // 延迟释放时长
int32 chunk_page_size; // 每一个chunk对应的page大小
int32 db_version_id; // db版本号,创建时写入,用于校验在不同版本的程序中是否兼容
char *start_addr; // db内存开始地址
char *end_addr; // db内存结束地址
AllocatorType allocator_type; // 分配器类型
MemInfo mem_info; // 内存信息
char version_str[Z_MAX_STRING_SIZE]; // 版本字符串
char create_pinfo[Z_MAX_STRING_SIZE]; // 创建的进程信息
Chunk chunk[Z_MAX_CHUNK_SIZE]; // 对应的chunk信息
AttachProcInfo proc[Z_MAX_DB_ATTACH_PROC_SIZE]; // 存储所有连接到这个db上面的所有信息
void *db_index_data; // 存储db的index信息
};
db的metadata中存放了进程创建db的一些详细信息,以及整个db的详细数据信息。
MemInfo信息
其中MemInfo是记录当前内存分配情况,具体结构体信息如下:
/**
* db内存信息
*/
struct MemInfo {
int64 used_bytes; // 实际申请的字节数
int64 fragment_bytes; // 因为fillbox时会产生碎片,这里记录浪费的字节数
FtHead ft_head; //记录内存块信息
};
内存块的详细结构如下:
/**
* ft内存分配器头
*/
struct FtHead {
FtBufList middle_box_list[Z_FT_MIDDLE_BOX_NUM]; //中等大小的块的数组
FtBufList small_box_list[Z_FT_SMALL_BOX_NUM]; //记录小块的数组
FtBufList page_list; //记录单独一个页的链表
};
其中Z_FT_MIDDLE_BOX_NUM 的大小是96块,每一个块之间的间隔大小为32个字节,Z_FT_SMALL_BOX_NUM的大小为128块每块间隔大小为8字节。FtBufList结构如下:
/**
* ft空闲buf链表
*/
struct FtBufList {
FtBufHead *head;
FtBufHead *tail;
};
/**
* 字节释放时的头
* 为节约内存空间,改用位域操作,原来存一个void * + uint32 要12个字节,现在只要8个字节
*/
struct FtBufHead {
uint32 timestamp_offset :24; // 起始时间改为从2016/01/01 01:01:01开始
uint64 next_offset :40; //地址指针起始为0x300000000000开始
};
可以看到内存使用了三个链表来记录分配的内存,其中小块和中块的内存记录通过对1k和4k内存划分区块,然后使用链表分别记录每个区块的具体分配地址。
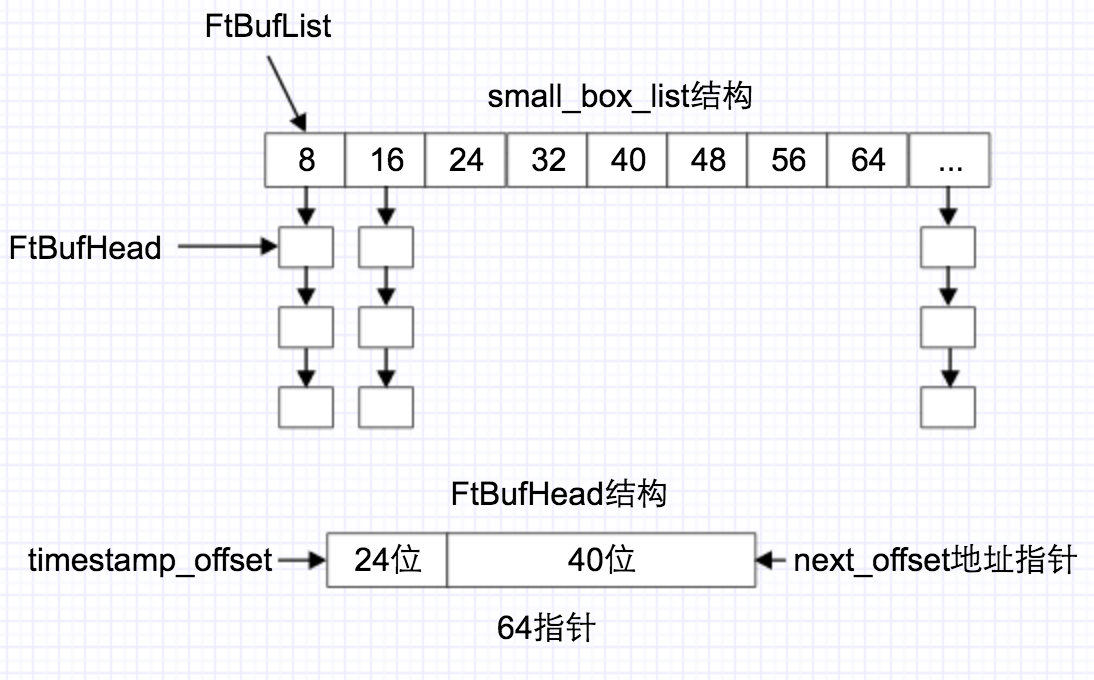
图中可以很详细看出,对内存进行详细的块大小分配,同时内存中为了实现rcu的延迟释放都存了一个时间戳,用于以后内存的释放。其中为了省内存,将一个64位的指针分为了前24位用于记录时间offset,这个时间offset是从2016/01/01 01:01:01开始的初始值是1451581261,并且时间offset不是简单的记录当前时间值,而是:
(now_time - 1451581261) / 30 //相当于记录时间缩小了30倍
可能是24位整数只能最多表示三年的秒数,所以缩小30倍相当于可以记录最多100年的时间offset。
Chunk块的信息
chunk块是对整个内存空间细分的一个大的db,每一个chunk块的大小为1GB。
Chunk chunk[Z_MAX_CHUNK_SIZE]; // 对应的chunk信息
Z_MAX_CHUNK_SIZE = 100; // 最多100个db
/**
* chunk信息
*/
struct Chunk {
size_t size; // 大小
ChunkStatus status; // 状态 1,未使用,2,正在attach3,正常情况
char *addr; // 起始地址
int32 free_page_num; // 剩余页数
int32 page_cursor; // 游标
int32 page_status[Z_CHUNK_MAX_SPACE_SIZE / Z_PAGE_SIZE / sizeof(int32)]; // 用一组bitset来表示页是否使用,0未使用,1使用
};
Z_CHUNK_MAX_SPACE_SIZE / Z_PAGE_SIZE / sizeof(int32) = 1GB / 4KB / 4字节 //这个长度是刚好用来记录该chunk块中所有4KB页的使用情况,相当于一个bitset的长度。
当每次申请新的内存页的时候,都会检查这个bitset中是否存在能够使用的连续长度的内存。
AttachProcInfo 进程attach信息
metadata里面还存放的有每个链接到db的进程详细信息,用于详细跟踪每个进程的详细状态,记录进程详细的结构如下所示:
/**
* 进程信息
*/
struct AttachProcInfo {
int32 pid; // 进程id
time_t attach_time; // 进程attach时间
time_t hb_update_time; // 进程心跳更新时间
int32 need_attach_chunk_no; // 当前进程需要attach的chunk no
char create_pinfo[Z_MAX_STRING_SIZE]; // 创建的进程信息
ProcPrivateInfo private_info; // 进程私有信息,内存放在进程内存中
};
/**
* 进程私有信息
*/
struct ProcPrivateInfo {
AttachProcHb *hb_thread; // 心跳线程
char db_root_path[MAX_PATH]; // db主路径
ProcPrivateChunk chunk[Z_MAX_CHUNK_SIZE]; // 私有chunk
};
/**
* chunk进程内私有信息
*/
struct ProcPrivateChunk {
char chunk_path[MAX_PATH]; // 对应的文件路径
int32 fd; // 对应的文件句柄
};
进程信息主要存放了进程id,进程touch到db的时间,进程私有信息包括每个进程的心跳信息,db的保存路径,打开db的文件描述符等详细信息。
index索引信息
void *db_index_data; // 存储db的index信息
这个是db中存放的所有索引的信息,该指针类型为DbIndexData*类型,具体详细索引信息如下
struct DbIndexData {
DbIndexData() : index_map(Z_DB_INDEX_TABLE_CAPACITY_SIZE),
param_map(Z_DB_PARAM_CAPACITY_SIZE) {
}
rcu_vector<zstring<true> > index_name_list; //全部索引名称
rcu_hash_map<zstring<true>, Index *> index_map; //存放全部索引指针
rcu_list<zstring<true> > param_list; //存放的一些chunk的参数list
rcu_hash_map<zstring<true>, zstring<true> > param_map; //具体的参数map数据
rcu_list<IndexImportRecord *> import_record; //记录所有import更新信息
};
至此db的metadata主要信息就暂时理清楚了。